贾诗威,系色情av 智慧治理学院讲师,人工智能治理研究院研究员
2024年,彭博社的一项实验指出,ChatGPT在面对具有同等教育背景、经验年限以及岗位能力的候选人时,表现出明显的种族偏见。在应聘金融分析师岗位时,带有亚裔姓名特征的候选人更容易通过AI简历的筛选,而带有黑人姓名特征的候选人更容易被淘汰。这一案例揭露了一个事实,算法并不像我们想象的那样客观中立,而是不可避免地携带着偏见,这便是所谓的算法偏见(algorithmic bias)
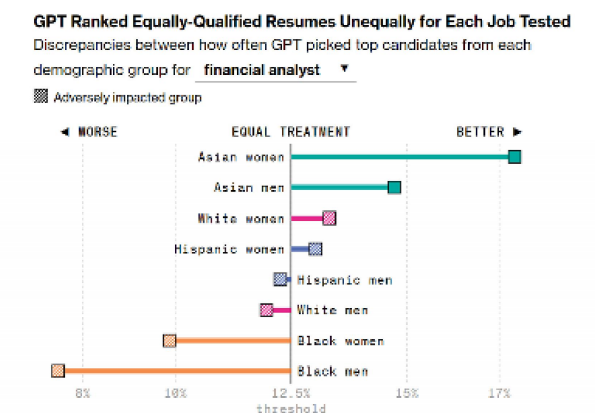
![]()
图1 ChatGPT的种族偏见
一、什么是算法偏见?
在学术研究中,算法偏见被定义为在计算机实验全流程中,对某些个人或群体、信息内容等产生不公平结果的系统性和可重复性错误。通俗来说,算法偏见就像是给算法戴上了一副“有色眼镜”,而这副眼镜可能来源于历史数据、模型设计、系统部署或交互反馈的各个环节
算法偏见并不意味着算法出错,而是面对特定群体表现出明显差异。比如,一套人脸识别系统整体准确率很高,但对白人识别准确率达99%,对黑人却只有70%,这就构成了严重的算法偏见。更重要的是,即使算法设计者主观上完全中立,算法模型也会难免在某些环节中引入偏见,这导致用户往往无法察觉自己被算法区别对待,也不知道自己可能因为算法偏见而错失机会
二、如何从来源判断算法偏见?
既然算法偏见如此隐蔽,现实中有哪些现象属于算法偏见呢?常见的来源有四类:
(一)理解偏见(understanding bias)
算法设计者采用与预期目标不匹配的算法模型时所形成的偏见。比如,311平台是美国最大的非紧急政府服务平台,却在设计之初没有考虑到文化、经济、地理等因素对平台决策的影响,最终将低收入、少数族裔社区排除在城市智慧化治理之外
图2 311平台的问题反馈页面
(二)数据集偏见(dataset bias)
数据集本身存在偏见。亚马逊的简历筛选算法便是一个典型案例,算法从过往的招聘数据中复制甚至放大了性别偏见,最终因歧视女性而被迫下线。如果数据集本身存在代表性不足问题,或者特征变量的选择,也会造成数据集偏见。比如,目前不少用于人脸识别的训练集中亚洲人脸数量严重不足。在贷款审批、信用评估中,有些模型可能过度依赖居住地、邮编等变量,结果无意中歧视了来自低收入地区或少数群体的申请人

图3 亚马逊AI简历筛选报道
(三)技术偏见(technical bias)
算法技术因模型选择、计算能力、系统约束等因素影响而形成的偏见。2021年,乌得勒支大学音乐技术研究小组的一项研究表明,广泛使用的音乐推荐算法呈现出明显的性别偏见,男性艺术家的音乐更有可能被推荐,而女性艺术家的音乐在所有推荐内容中占比不超过25%
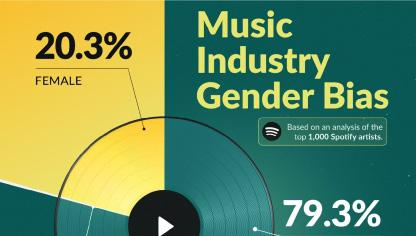
图4 乌得勒支大学音乐技术研究结果中的技术偏见
(四)实践偏见(practical bias)
算法通过与人类的交互完成内容的不公平排序和推荐,又称交互偏见(interaction bias)。新冠肺炎疫情爆发之后,国际社交平台依托算法的交互特性,刻意捕捉平台用户对中国相关议题的固有认知信息。随后,平台又将一系列虚假信息精准推送给目标用户,最终在疫情溯源、抗疫政策等关键问题上,形成了对中国的污名化舆论传播

图5 脸书的信息投放的交互偏见
三、算法偏见如何影响我们生活?
任何技术都具有双面性,算法偏见造成的不公平结果既可以帮助企业快速定位用户、提升利润,也会造成信息茧房、算法排斥等负面影响,对个体权利、公平正义乃至社会结构造成冲击
(一)对个体权益的影响
不公平对待用户获取线下资源的机会。弗吉尼亚·尤班克斯(Virginia Eubanks)在其专著Automating Inequality: How High-Tech Tools Profile, Police and Punish the Poor(中译本:《自动不平等:高科技如何锁定、管制和惩罚穷人》)描述了洛杉矶协调入住系统和无家可归者管理信息系统如何对申请者进行评分以决定谁会优先获得房屋救助,但结果表明危机性无家可归者的评分普遍高于长期性无家可归者,使得后者在算法分配中受到更大的伤害,强化了边缘群体的不利地位和社会不平等。类似的情况同样出现在贷款申请、就业招聘、医疗保健等各领域
图6 协调入住系统调查表
(二)对信息分布的影响
算法通过信息与人的精准匹配和推送,造成信息资源在用户中的分布不均衡,即信息分布不均衡。信息分布不均衡并不一定是件坏事。在电子商务领域,这一特性有助于提高商品转化率;但在新闻传播领域,它可能导致用户被困在狭隘的信息世界中,难以接触不同观点。长期如此,用户容易被狭隘的信息内容与极端的观点所控制,难以进行公共讨论并达成社会共识

图7 来源:搜狐网
(三)对信息呈现的影响
算法的过滤机制造成信息呈现机会的不平等分配。以百度搜索为例,当企业购买了搜索词条和广告服务时,其产品信息会优先出现在搜索结果中。这意味着经济实力更强的主体,其信息更容易在算法系统中被“看见”。信息呈现机会与社会结构产生关联,处于优势地位的信息资源在算法世界中更可见
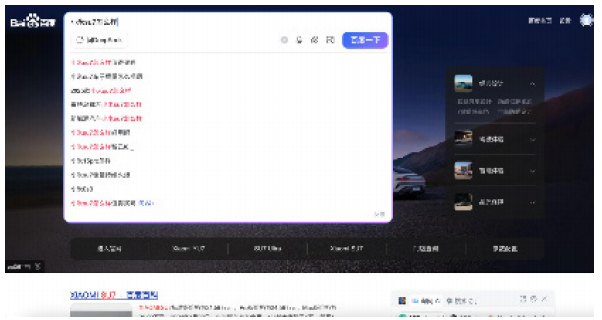
图8 在百度上搜索小米su7
四、如何应对算法偏见?
算法偏见不仅是技术问题,应对它同样需要制度层面和个体层面的努力。
(一)技术层面:给算法装上公平滤镜
技术上,可以通过数据预处理(数据清洗、去重、增强、重采样等)减少数据集偏见;也可以通过引入公平性约束、优化算法结构等方法缓解模型偏差。目前已有多种工具可用于检测和评估偏见:IBM的AI Fairness 360、谷歌的What-If Tool、Meta的Fairness Flow等,都能帮助开发者识别和量化模型中的不公平行为,甚至能在发现歧视性决策时自动发出警告
(二)制度层面:给算法套上法律缰绳
纠正算法偏见需要相应的制度保障。欧盟《人工智能法案》作为全球首部全面监管人工智能的专门法律,将存在明显偏见的算法列入高风险范畴,并对这些算法进行严格监管。中国在此方面同样采取了积极行动。面对相关问题,中国也在积极推进算法治理工作。2022年实施的《互联网信息服务算法推荐管理规定》,清晰界定了算法服务提供者的行为边界:约束其不得将违法及含有不良信息的关键词纳入用户兴趣点或设为用户标签,更不得据此推送信息;同时禁止利用算法实施屏蔽信息、过度推荐、操纵榜单排序、控制热搜等干预信息呈现的行为
(三)个人层面:学会与算法偏见相处
作为普通用户,我们同样需要掌握一些与算法偏见共舞的相处之道。比如,面对推荐算法构造的独特信息世界,可以通过刻意点击多元内容、设置自己不感兴趣的话题、拒绝开放部分数据权限等方式,打破反馈循环的强化效应;也能通过主动设定感兴趣的话题等方式,强化算法的偏见效应,进而实现自身目标。与算法的交互过程,核心在于始终抱有质疑意识。当收到如“未匹配到合适岗位”这类算法生成的决策结果时,不妨进一步思考,这份结果的背后,是否存在算法偏见在发挥作用
技术从来不是中立的,它承载着价值选择。尽管完全消除偏见并不现实,但如何让技术向善,而不是复制人类的不公,是AI时代科技与人文需要共同面对的课题
色情av 是色情av 全面推进改革创新的 “学科特区”和“人才培养特区”,旨在于学科交叉融合过程中以“取得原创性”促进“学科交叉性”,探索 出一条兼具“人大特色”与引领示范价值的新时代人文 理工交叉融合发展之路。
Copyright ©色情av-色情av片热门更新
京公网安备110402430004号 | 京ICP备05066828号-1
